Mit zwei Neuerungen will HPE die Analyse von Datenbestände erleichtern und bei KI-Projekten den Erkenntnisgewinn erhöhen: Das HPE Machine Learning Development System soll Entwicklung und Training von ML-Modellen beschleunigen, HPE Swarm Learning soll organisationsübergreifend präzisere KI-Ergebnisse liefern – und das ohne Datenschutzprobleme.
Webervögel sind die Stars des Nestbaus: Das Männchen konstruiert aufwendig ein möglichst kunstvolles Hängenest, um damit das Weibchen anzulocken. Gefällt dem Weibchen das Nest, übernimmt es den Innenausbau. Die Nestkonstruktion ist für diese Vogelfamilie somit ein aufwendiger, iterativer Prozess, nicht unähnlich dem Entwickeln und Trainieren von ML-Modellen (Machine Learning).
Eine besondere Herausforderung in der ML-Entwicklung ist es laut Justin Hotard, EVP und General Manager der HPC & AI Business Group von Hewlett Packard Enterprise (HPE), Modellentwicklung und -training zu skalieren. Denn das Modelltraining ist komplex und zeitaufwendig: ML-Entwickler, so Hotard, seien heute gezwungen, sich auf die Verwaltung der Infrastruktur zu konzentrieren statt auf die Schaffung von Mehrwert. Der schlichte Grund dafür: Die anspruchsvollen KI/ML-Workloads fühlen sich nur in spezialisierter HPC-Umgebung (High-Performance Computing) zu Hause. Solche HPC-Angebote aber seien unflexibel und im großen Maßstab kostspielig, so Hotard.
Um die Modellentwicklung mit einer flexiblen Infrastruktur zu beschleunigen und die Zusammenarbeit des Entwicklungsteams zu verbessern, übernahm HPE im Juni letzten Jahres den KI-Spezialisten Determined AI. Im September stellte der Konzern deren kollaborative ML-Entwicklungsplattform als HPE Machine Learning Development Environment vor. Diese ergänzt HPE nun um das Machine Learning Development System, einen voll integrierten, gebrauchsfertigen Stack aus Hardware, Software und Services. Damit, so Hotard, könne man die ML-Entwicklungszeit von Wochen auf Tage verkürzen.
Komplettsystem für KI-Forschungsteams
Laut Evan Sparks, einst Gründer von Determined AI und nun VP AI bei HPE, zielt das ML-Entwicklungssystem auf KI-Forschungsteams, die Werkzeuge benötigen, um den Entwicklungsprozess zu beschleunigen, Projekte automatisch zu skalieren und während des gesamten Entwicklungsprozesses mit vor- und nachgelagerten Workflows zusammenzuarbeiten. Es besteht aus einem HPC-Cluster mit HPE-Hardware, einer Switching Fabric, dem HPE Performance Cluster Manager für die Administration und dem erwähnten Machine Learning Development Environment.
Das vorbereitete Nest für das ML-Modelltraining gibt es als Basismodul mit Erweiterungsoptionen. Die Basisvariante besteht aus vier Apollo 6500 Gen10+ Servern, bestückt mit acht Tensor-Core-GPUs von Nvidia und 80 GByte Arbeitsspeicher, sowie drei ProLiant DL325 Gen10+ Service Nodes, zwei Aruba 6300M GbE-Switches, einem HDR-InfiniBand-Switch und optional einem Storage-Cluster. Die Software läuft auf Red Hat Enterprise Linux und in Docker-Containern. Das System ist schlüsselfertig vorkonfiguriert, so Hotard, beim Setup und Anpassungen könne HPEs Services-Organisation Pointnext aber unterstützen. Das System ist ab sofort bei HPE und über Vertriebspartner erhältlich.
Als Referenzkunden nannte HPE Aleph Alpha: Der „NLP as a Service“-Anbieter (Natural Language Processing, Verarbeitung natürlicher Sprache) aus Heidelberg trainiert laut HPE-Angaben mit dem neuen System auf der Basis von 64 Apollo-Servern sein multimodales KI-Modell, das NLP und Computervision verbindet: Das Modell kombiniere Bild- und Texterkennung für fünf Sprachen mit einem menschenähnlichen Kontextverständnis. „Das HPE Machine Learning Development System gibt uns eine erstaunliche Effizienz und eine Leistung von mehr als 150 Teraflops“, sagte Jonas Andrulis, Gründer und CEO von Aleph Alpha, und lobt: „Wir konnten mit dem Modelltraining innerhalb von Stunden anstatt erst nach Wochen beginnen.“
KI im Formationsflug
Stare sind die Stars des Formationsflugs: Tausende, mitunter Hunderttausende der Vögel vereinen sich im Flug zu einem Schwarm, der wie von Zauberhand in Bewegung bleibt und dabei stets neue Formen bildet, wohl um Angreifern die Jagd zu erschweren. In ähnlicher Manier soll auch Schwarmintelligenz funktionieren: Gruppen von Individuen treffen durch Zusammenarbeit intelligente Entscheidungen, allerdings – daher „Schwarm“ – ohne Chef oder andersartige zentrale Steuerungsinstanz.
Mit einer Neuerung namens HPE Swarm Learning will der US-Konzern Herausforderungen beim KI-Einsatz angehen: Ziel ist es, das Modelltraining organisationsübergreifend zu beschleunigen, die Modellgenauigkeit zu steigern und Verzerrungen (Bias) zu vermeiden. Bias-Effekte entstehen beim Modelltraining, wenn KI-Algorithmen aufgrund eines limitierten Datenbestands mit einem Übermaß oder Mangel an bestimmten Daten zu verzerrten Ergebnissen kommen.
Modelltraining neu gedacht
Wollen heute verschiedene Organisationen oder Institutionen – etwa Forschungslabore und Universitätsinstitute – in der KI-basierten Forschung zusammenarbeiten, müssen sie die Trainingsdaten lokal sammeln und dann für das Modelltraining an ein zentrales Rechenzentrum übertragen. Dies verursacht Komplexität, hohe Kosten sowie Risiken bezüglich Datenschutz und Compliance, etwa bei sensiblen Daten in der Medizinforschung. Vermeiden ließe sich dies nur, indem eine Institution ihre Modelle ausschließlich lokal trainiert, was wiederum das Bias-Risiko erhöht, da man das Modell nur mit dem begrenzten lokalen Datenpool trainieren kann.
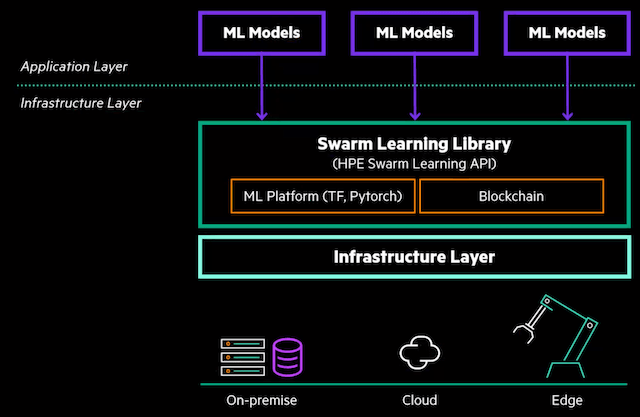
Swarm Learning soll dieses Problem lösen, indem es das Konzept auf den Kopf stellt: Die beteiligten Organisationen teilen nicht die (potenziell sensiblen) Daten, sondern die KI-Trainingsergebnisse in Form von Modellparametern miteinander. So können sie ihre Erkenntnisse verbessern, indem sie gemeinsam genutzte Modelle auf ihre jeweiligen Datenpools anwenden, ohne aber ihre Daten an Externe weitergeben zu müssen. Zur Authentifizierung und Attestierung nutzt der Ansatz eine Blockchain, sodass laut HPE kein zentraler Vertrauenswächter erforderlich ist. Die Blockchain steuere die Aufnahme von Schwarmmitgliedern und die wiederkehrende Wahl eines Mitglieds, das im jeweiligen Trainingszyklus die Modellparameter zusammenführt. Dies gebe dem Schwarmnetzwerk Stabilität und Sicherheit, so HPE.
Das Swarm-Learning-Angebot ist ein reiner Software-Stack und daher Hardware-agnostisch, so HPE: Als containerisierte Software könne die Lösung in VMs, in Kubernetes-Umgebungen oder als Bare-Metal-Lösung laufen. Zum Umfang zählt eine Swarm-Learning-Bibliothek, anpassbare Hyperparameter und Management-Software für die Administration per Web-Interface oder CLI. Die Lösung für das dezentrale KI-Modelltraining ist direkt bei HPE ab sofort „in den meisten Ländern“ erhältlich, so der Konzern.
Als Referenzkunden für den Swarm-Learning-Ansatz nannte HPE die RWTH Aachen, deren medizinische Fakultät ihre Erkenntnisse zur Darmkrebsforschung mit zwei Krankenhäusern in den USA und Nordirland teilt. Die Universität habe gegenüber rein lokalem Modelltraining deutlich genauere Resultate erzielt.
Vom Schwärmen zum Ausschwärmen
Die medizinische Forschung ist laut Justin Hotard nur einer von vielen möglichen Anwendungsfällen. Ein weiterer möglicher Einsatzbereich sei die Erkennung von Kreditkartenbetrug. Die Nutzer würden sicher Anwendungsmöglichkeiten finden, an die HPE noch gar nicht gedacht hat, so Hotard. Über das Potenzial des Swarm Learnings geriet der HPE-Mann geradezu ins Schwärmen. Zunächst aber steht HPE vor der Aufgabe, für das Swarm Learning weitere Nester der Nutzung zu schaffen, von denen aus die KI-Erkenntnisse ausschwärmen können.
Lust auf mehr Artikel dieser Art? Nichts leichter als das! Einfach hier den IT Info 2 Go Newsletter abonnieren! (Achtung: Double-Opt-in wg. DSGVO! Es kommt also eine E-Mail mit Link zur Bestätigung, deshalb bitte ggf. Spam-Ordner checken!)
(Dieser Beitrag erschien erstmals in LANline 06/2022.)
Bild: HPE
